

AI for open-ended scientific explanations
LLM Kernel, a framework for evaluating explanatory reasoning



Language models in discovery research
At Transcripta Bio, our mission is to decode the language of biology to engineer medicines for patients. To achieve this, we see an important role for artificial intelligence as a partner in scientific discovery.
Progress in science is not just about accurate prediction; it’s about building strong explanations. This is particularly true in discovery research, where we venture into the unknown and the concept of a “ground-truth” answer often doesn’t exist. For language-based AI to be a trustworthy collaborator, its reasoning must be transparent and evaluable in open-ended domains.
This challenge is different from automation. Recently, a class of agentic workflow systems—often referred to as scientific copilots—has emerged. Platforms like Biomni and ToolUniverse accelerate research tasks by orchestrating agents to perform data analysis, providing operational speed to existing workflows.
These systems are already impacting scientific practice. However, we believe a complementary form of AI—one that can propose explanations for complex phenomena in the same way a human scientist does—is just as critical for the future of science.
Our recent work addresses this challenge through LLM Kernel, a framework for evaluating the explanatory reasoning of language models in open-ended scientific domains. This research has been accepted to the NeurIPS 2025 AI for Science Workshop.
Beyond automation and towards explanation
While scientific copilots are becoming effective for automating typical procedures, they don’t address the core challenge of discovery research: evaluating the quality and validity of scientific explanations themselves.
Our work on LLM Kernel takes a different path. Instead of building a faster lab assistant, we aim to create a verifiable scientific partner. The goal isn’t just to get an answer more quickly, but to understand if an explanation is valid by measuring the AI’s reasoning process.
LLM Kernel
In discovery research, we can’t just check an answer against a textbook. So, how can we build evidence for explanations?
Our framework draws on a long-standing principle of scientific reasoning: comparison. Many discoveries emerge from recognizing patterns of similarity or deviation—seeing when phenomena behave alike or when one diverges from the expected pattern. This idea is also present in many common statistical methods that use notions of similarity to reveal structure in data.
In transcriptomics, for instance, we often compare gene expression profiles using metrics like cosine similarity, expecting that drugs with related mechanisms of action will yield similar transcriptional responses and thus cluster together. Kernel-based methods generalize this notion, enabling systematic comparisons across rich scientific data types.
LLM Kernel extends this comparative framework to language models. Instead of a fixed mathematical metric, it leverages an LLM’s capacity to ingest unstructured data and reason through analogies and contrasts.
Given two samples, the model produces:
A qualitative reasoning trace — a human-readable explanation of the biological similarities and differences it identifies.
A quantitative similarity score (ranging from -1 to 1) — a single value summarizing its judgment of how similar the samples are.
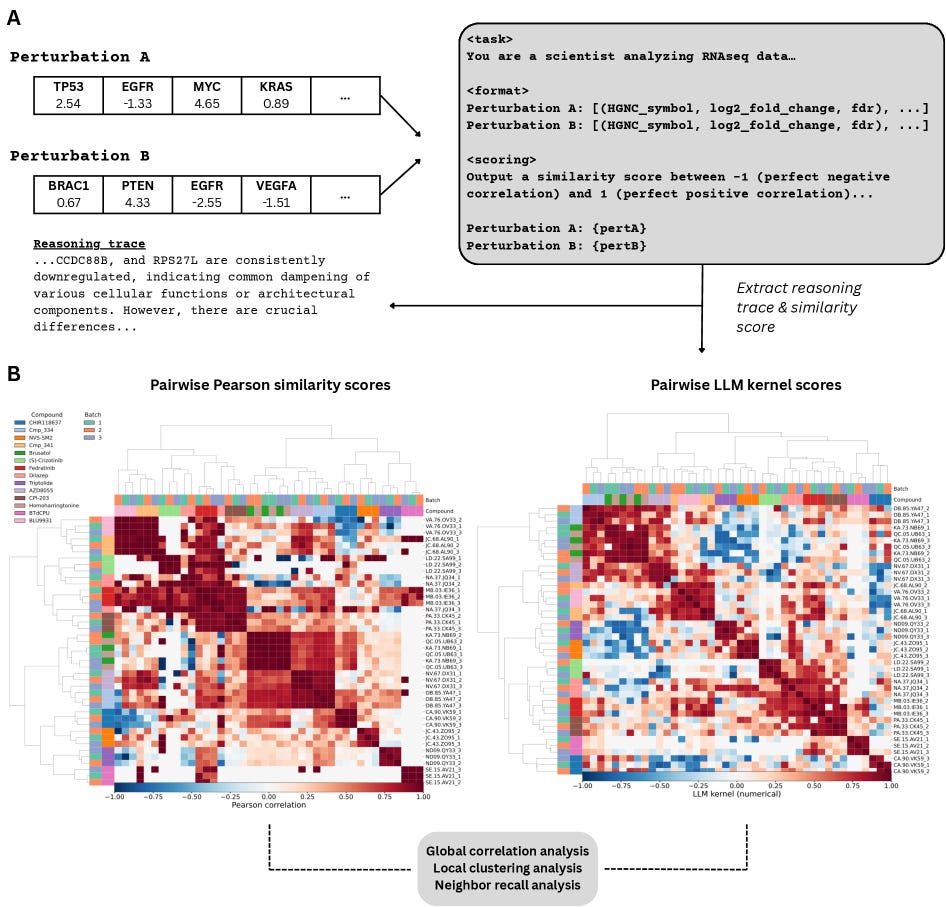
This framework forces the model to commit to a testable conclusion: a numerical score that follows directly from its scientific reasoning. Because the explanation precedes the score, we can evaluate not just what the model concludes, but why.
In discovery research, absolute labels are rare, but relative information is abundant: we often know when one sample behaves more like another. By framing the task as a set of pairwise comparisons, unlabeled samples can be organized by multiple notions of similarity.
Unlike classification, which constrains interpretation to a fixed set of predefined categories, similarity scoring allows explanations to emerge directly from the data. Free from coarse labels such as pathways or mechanisms, the model can explore patterns without bias toward existing frameworks, enabling novel associations.
When the LLM kernel produces similarity patterns that align with known sample relationships, it provides evidence that the model’s reasoning is scientifically meaningful—making explanation itself measurable.
Key scientific findings
We applied LLM Kernel to a large-scale transcriptomics dataset to distinguish between compounds with various molecular effects.
Superior performance
LLM Kernel consistently outperformed standard numerical methods like Pearson and Spearman correlation in identifying biological relationships. We found that performance scaled with the computational budget of the model—giving the model more “thinking time” resulted in better similarity scores!
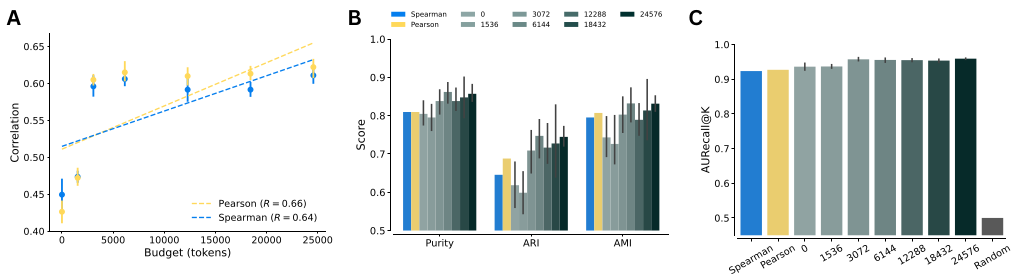
Dependence on biological knowledge
Ablation experiments revealed that the model’s success depends on access to biological context, not just statistical patterns. When gene names were masked, performance dropped sharply. Additional ablations confirmed that the LLM Kernel relies on prior knowledge of gene function and pathway structure rather than merely reproducing numerical correlations.

Cross-modal reasoning
A unique feature of LLM Kernel is its ability to compare completely different data types. We introduced a novel challenge: score the similarity between a natural language description of a disease (e.g., Alzheimer’s disease) and a numerical gene expression profile from a drug-treated cell line. The method was able to identify compounds with known relevance to specific diseases by recognizing cellular responses that complemented each disease description—an impossible task for traditional numerical methods (see Figure 3 of the paper).
Open questions
A key limitation is that while our framework links each similarity score to an explanation through a causal chain of tokens, we don’t yet know the precise origin of that score. Is it truly the product of the detailed reasoning we see, or does it emerge from implicit computations?
Our finding that scores improve with more “thinking time” suggests performance is tied to the volume of computation—not necessarily the quality of the reasoning itself. Understanding the relationship between computation and the accuracy of produced content is a central question in modern AI research, and LLM Kernel may provide a new tool to investigate it.
The road ahead
Using AI to accelerate science may be the most impactful way we apply intelligence technology. LLM Kernel represents a step toward building auditable and verifiable AI for scientific discovery.
Through pairwise comparison, we transform unlabeled scientific data into a series of testable relationships—small, data-driven judgments that reveal how well the model understands biology. By coupling qualitative reasoning with a quantitative, benchmarkable score, we can begin to open up the “black box” of AI’s reasoning and build trust in its interpretations.
This framework provides a scalable way to evaluate and improve the quality of AI-driven scientific insight, paving the way for systems that can act as true partners in the quest to understand and engineer biology.
For a deeper dive into our methods and results, please check out the paper and code.
📄 LLM Kernel: an evaluation framework for open-ended scientific interpretation